
Cualquier cientista social que haya hecho una entrevista, focus group u otro tipo de trabajo cualitativo, sabe lo tedioso que resulta la transcripción de audio a texto. Estar constantemente retrocediendo el audio para escuchar mejor, no poder escribir a la velocidad que se habla, y dedicar horas a transcribir contenido largo, son tareas sumamente monótonas. Para peor, la mayoría de los programas gratuitos para la automatización de este proceso suelen ser de baja calidad, están especializados para transcripciones en inglés, y/o son deficientes reconociendo modismos o el español hablado en contextos específicos.
En este artículo usaremos una herramienta gratuita que soluciona muchos de estos problemas con una muy buena tasa de efectividad, incluyendo marcadores de tiempo y soporte para prácticamente cualquier formato de audio. ¡Prepárense para decirle adiós a horas de transcripción manual!
¿Qué es Whisper?
Whisper es un modelo de inteligencia artificial de código abierto (Open Source) presentado por OpenAI (los creadores de ChatGPT). Este modelo fue entrenado con un conjunto de datos gigantesco, lo que le permite tener un excelente rendimiento en tareas multilingües, incluso con ruido ambiental y con distintos acentos. A pesar de que este proyecto fue lanzado en 2022, Whisper sigue recibiendo actualizaciones con un rendimiento cada vez mejor. Es importante destacar que Whisper tiene una tasa de error muy baja en español, llegando a tener incluso mejor rendimiento en nuestro idioma que en inglés para ciertas aplicaciones.
Sin embargo, no todo es color de rosas. Whisper puede tener una barrera de entrada algo alta para el cientista social promedio, que no necesariamente tiene los conocimientos de programación requeridos para usarlo directamente. Es el objetivo de este artículo ayudar a superar esta barrera de entrada y hacer más accesible esta maravillosa herramienta.
Nota para los que solo quieran usar la herramienta de la manera más fácil:
Si solo quieres usar la herramienta, al final del tutorial he dejado un cuaderno de Colab con todo el material listo. Solo necesitas abrirlo, subir tus archivos y ejecutar los pasos.
Paso 1: Acceder a Google Colab
Google Colab es una herramienta que nos permite ejecutar código de Python online, además de prestarnos máquinas virtuales con buenos recursos computacionales, incluyendo acceso gratuito a GPUs, esenciales para tareas de inteligencia artificial como esta.
Para acceder a Colab, entramos a colab.google, y hacemos click en New Notebook.
Si no han ingresado su cuenta de Google, les pedirá que inicien sesión. Después de esto, se creará un cuaderno de Python, y estaremos listos para trabajar.
Paso 2: Uso de GPU, instalación de Whisper y dependencias
En primer lugar, debemos asegurarnos que Colab esté usando una GPU para acelerar drásticamente el procesamiento. Para ello, seguiremos los siguientes pasos:
- En la parte superior derecha de la pantalla, encontraremos el botón "Conectar". Justo a su lado, veremos una flecha pequeña hacia abajo. Haremos click aquí.
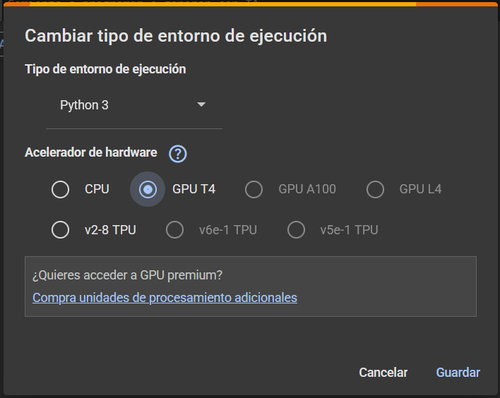
- Luego, debemos seleccionar la opción "Cambiar tipo de entorno de ejecución". En este menú, debemos marcar la opción "GPU T4" y luego cerrar el menú con el botón "Guardar".
Ahora, vamos a instalar `faster-whisper`. Esta es una versión optimizada de Whisper que procesa el audio más rápido sin perder precisión. Para ello, en la primera celda de código de tu cuaderno, escribe o pega lo siguiente y ejecútala (haciendo click en el botón de "play" a la izquierda de la celda o presionando Shift+Enter):
[[CODE:python]]
!pip install faster-whisper -qqq
[[/CODE]]
A continuación, importaremos las librerías necesarias. En una nueva celda de código, escribe y ejecuta:
[[CODE:python]]
from faster_whisper import WhisperModel
[[/CODE]]
Paso 3: Cargar el modelo y los archivos de audio
Cargar el modelo Whisper
Para cargar el modelo de transcripción, simplemente tenemos que ejecutar en una nueva celda:
[[CODE:python]]
model = WhisperModel("large-v3")
[[/CODE]]
El modelo quedará cargado en el elemento "model". En este caso, utilizaremos la versión "large-v3". Esta es la más precisa a la fecha de este tutorial. Este código tomará un tiempo para ejecutarse, así que hay que ser pacientes, ya que estaremos cargando un modelo de gran tamaño.
Cargar el archivo de audio
Para cargar el archivo de audio que queremos transcribir, tenemos dos opciones principales: podemos cargarlo desde nuestra cuenta de Google Drive, o podemos subirlo directamente desde nuestro computador al entorno de Colab.
Opción A: Desde Google Drive (Recomendado)
Para cargar el archivo desde Google Drive, tenemos que saber en que carpeta de Drive se encuentra nuestro archivo. Para hacer un ejemplo gráfico, crearé una nueva carpeta usando el botón Nuevo en la parte superior izquierda de nuestra página principal de Drive.

Habiendo hecho esto, habremos creado una carpeta en la raíz de nuestro drive. En esta carpeta debemos subir nuestro archivo de audio de preferencia.
Luego, necesitamos montar nuestro directorio de Drive al cuaderno. Para esto, debemos clickear en el símbolo de carpeta que se encuentra en el lado izquierdo de la pantalla.
Luego, clickeamos en el ícono de drive:
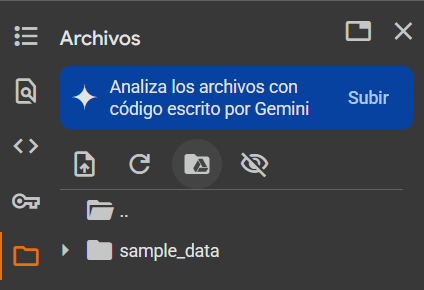
Aceptamos conectarnos con Google Drive, y tras unos segundos, podremos acceder a Drive en las carpetas del cuaderno.
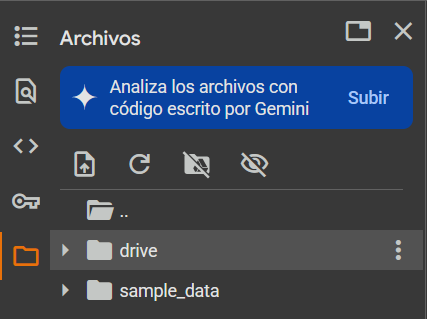
Debemos abrir esta carpeta y buscar nuestro archivo en el Drive. Una vez lo encontremos, debemos hacer click en los tres puntos y luego clickear "Copiar la ruta de acceso". La necesitaremos más tarde.

Opción B: Subir directamente al entorno de Colab (Solo recomendable para pruebas rápidas o archivos pequeños)
Si prefieres no usar Google Drive o tienes un archivo puntual, puedes subirlo directamente al entorno de Colab:
- Haremos click en el ícono de carpeta en el menú de la izquierda (el mismo que usamos para montar Drive).
- Verás un ícono de "Subir" ( una hoja de papel con una flecha hacia arriba). Lo clickearemos.
- Selecciona el archivo de audio desde tu computador
- Una vez subido, aparecerá en el panel de archivos, en la carpeta raíz (`/content/`). Haz click derecho sobre el archivo y selecciona "Copiar la ruta de acceso". Esta ruta será algo como `/content/nombre_de_tu_archivo.mp3`.
Importante: Los archivos subidos de esta manera son temporales, y se borarrán cuando cierres la sesión de Colab o esta se reinicie por inactividad. Si necesitas que los archivos y transcripciones persistan, usa el método de Google Drive.
(Opcional pero recomendable) Transformar formato de audio a .wav
Aunque Whisper acepta varios formatos de audio, suele funcionar mejor con formatos sin compresión como `.wav`. Además, si tu audio está en un formato que Whisper no reconoce directamente (como algunos `.m4a` o formatos menos comunes), necesitarás convertirlo.
Primero, instalamos una librería para manipulación de audio llamada `pydub`. En una nueva celda:
[[CODE:python]]
!pip install pydub -qqq
[[/CODE]]
Luego, en otra celda, ejecutamos el siguiente bloque de código. No olvidar modificar la ruta de los archivos:
- `ruta_audio_original`: Pon aquí la ruta que copiaste de tu archivo de audio original (ya sea de Drive o subido directamente).
- `ruta_audio_wav_salida`: Define dónde quieres guardar el archivo `.wav` convertido. Si usas Drive, asegúrate de que la carpeta exista. Si subiste el archivo directamente, puedes guardarlo como `/content/audio_procesado.wav`.
- `formato_original`: Cambia `"mp3"` por el formato de tu archivo original (ej. `"m4a"`, `"ogg"`).
[[CODE:python]]
# Cargamos pydub
from pydub import AudioSegment
# CONFIGURAR ESTAS RUTAS
ruta_audio_original = "/content/drive/MyDrive/carpeta de ejemplo/ejemplo.mp3"
formato_original = "mp3"
# Definimos dónde guardar el archivo WAV procesado
# Si usamos Drive, es necesario asegurarse de que la carpeta exista
ruta_audio_wav_salida = "/content/drive/MyDrive/carpeta de ejemplo/audio_procesado.wav"
# Si subiste el archivo directamente y quieres guardarlo en Colab (temporal):
# ruta_audio_wav_salida = "/content/audio_procesado.wav"
# ---- Fin de la configuración ----
# Ejecución de la transformación:
audio = AudioSegment.from_file(ruta_audio_original, format=formato_original)
audio.export(ruta_audio_wav_salida, format="wav")
[[/CODE]]
Paso 4: ¡Transcripción!
Este es el momento donde le pediremos a Whisper que transcriba nuestro audio.
Es necesario asegurarnos de que la variable `ruta_del_audio_a_transcribir` apunte al archivo correcto:
- Si convertiste tu audio a `.wav`, esta ruta debe ser `ruta_audio_wav_salida` del paso anterior.
- Si no lo convertiste y tu formato es compatible (ej. un `.mp3` que Whisper suele leer bien), usa `ruta_audio_original`.
[[CODE:python]]
ruta_del_audio_a_transcribir = "/content/drive/MyDrive/carpeta de ejemplo/audio_procesado.wav" # EJEMPLO: Cambia esto
# Ejemplo si no convertiste y tu audio es mp3 directo de Drive:
# ruta_del_audio_a_transcribir = "/content/drive/MyDrive/carpeta de ejemplo/entrevista_01.mp3"
# Ejemplo si subiste un archivo directamente a Colab y no convertiste:
# ruta_del_audio_a_transcribir = "/content/entrevista_01.mp3"
# --- FIN DE LA CONFIGURACIÓN INICIAL ---
# --- Configuración de las rutas de salida para las transcripciones ---
# Es necesario asegurarnos de que la carpeta que indiquemos efectivamente exista si escogimos esa opción
# Por ejemplo, crearemos los archivos en una carpeta "Colab Notebooks" que Colab suele usar o puedes crearla tú.
ruta_salida_timestamps = "/content/drive/MyDrive/Colab Notebooks/transcripcion_con_timestamps.txt"
ruta_salida_solo_texto = "/content/drive/MyDrive/Colab Notebooks/transcripcion_solo_texto.txt"
# --- FIN DE LA CONFIGURACIÓN ---
# Ejecución de la transcripción
segments, info = model.transcribe(ruta_del_audio_a_transcribir)
print(f"Idioma detectado: {info.language} con probabilidad {info.language_probability}")
print(f"Duración del audio: {info.duration} segundos")
# Guardado de la transcripción con marcas de tiempo
with open(ruta_salida_timestamps, "w", encoding="utf-8") as f:
print(f"\nGuardando transcripción con timestamps en: {ruta_salida_timestamps}")
for segment in segments:
# El formato es [tiempo_inicio -> tiempo_fin] Texto del segmento
f.write("[%.2fs -> %.2fs] %s\n" % (segment.start, segment.end, segment.text.strip()))
# Guardado de la transcripción solo con texto
with open(ruta_salida_solo_texto, "w", encoding="utf-8") as f:
print(f"\nGuardando transcripción solo texto en: {ruta_salida_solo_texto}")
texto_completo = ""
for segment in segments:
texto_completo += segment.text.strip() + " " # Agregamos un espacio entre segmentos
f.write(texto_completo.strip()) # Escribimos todo el texto junto
print("Los archivos han sido guardados. Puedes encontrarlos en las rutas que especificaste.")
[[/CODE]]
IMPORTANTE SI SUBISTE EL AUDIO DIRECTO A COLAB
Si subiste el audio directamente a Colab, puedes guardar las transcripciones también en Colab (ej. `/content/transcripcion.txt`). Recuerda descargar estos archivos a tu computador antes de cerrar la sesión de Colab, ya que se borrarán. Para descargar un archivo desde el panel de archivos de Colab, haz click en los tres puntos junto al nombre del archivo y selecciona "Descargar".
Paso 5: Revisar los resultados
Una vez el código anterior termine de ejecutarse, (a veces puede tardarse varios minutos para audios largos), tus archivos de transcripción ya estarán listos.
- Si los guardaste en Google Drive, navega a la carpeta correspondiente en tu Drive y ábrelos.
- Si los guardaste en el entorno de Colab, puedes descargarlos desde el panel de archivos de Colab a tu computador.
Ejemplo de contenido con timestamps:
[[CODE:bash]]
[0.00s -> 11.16s] Hola, me llamo Matías, estoy aprendiendo a usar Whisper, estudio Sociología y estoy usando Google Colab.
[11.50s -> 15.30s] Esta herramienta parece muy útil para mis investigaciones.
[[/CODE]]
Ejemplo solo con texto:
[[CODE:bash]]
Hola, me llamo Matías, estoy aprendiendo a usar Whisper, estudio Sociología y estoy usando Google Colab. Esta herramienta parece muy útil para mis investigaciones.
[[/CODE]]
¡Y listo! Ya tienes tu audio transcrito.
Sugerencias adicionales y buenas prácticas
- Aunque Whisper es muy preciso, no olvides darle una revisión al texto transcrito, para corregir detalles, especialmente con nombres propios o jerga muy específica. En mi experiencia personal, Whisper tiene pocos problemas con nombres propios, incluso de entidades chilenas, pero nunca está de más tener cuidado con esto.
- Sobre la calidad del audio: Aunque Whisper haga un buen trabajo incluso con audio sucio, es mucho más fácil tener un buen resultado si la calidad del audio original es buena. Intenta grabar en ambientes con poco ruido y con el micrófono cerca de la fuente de sonido.
- Archivos Largos: Para audios muy largos (más de 1 hora), el proceso puede tardar bastante. Sé paciente. Colab tiene límites de tiempo para sesiones gratuitas, así que para trabajos muy extensos, considera dividir el audio
- Es recomendable que guardes el Notebook de Colab y hagas tu propia copia.
- Sobre múltiples hablantes: Whisper no diferencia hablantes en la transcripción. Si necesitas identificar que hablante dijo que, puedes hacerlo manualmente o usar herramientas alternativas especializadas en diarización (la separación de hablantes) (ejemplo).
Esperamos que este tutorial sea de gran utilidad para tus proyectos de investigación, y sea capaz de ahorrarte horas de frustración. No dudes en contactarte con el autor de este tutorial si te surgen dudas o estás teniendo algún inconveniente.