
Datamedios: un paquete para la extracción, procesamiento y visualización de noticias
El paquete `datamedios` permite extraer noticias de múltiples fuentes. Actualmente de El Mercurio (noticias no pagas), los diarios regionales de El Mercurio y de la guioteca, además de BíoBío.cl, el medio que, según el Reuters Institute Digital News Report 2024, sería al que más se le tiene confianza dentro de los medios estudiados y es también de los más consultados.
En este tutorial exploraremos una forma de utilizar el paquete para analizar la cobertura de la crisis hídrica en Chile. Debemos recalcar que esto es solo un ejemplo y no la única forma de utilizar dicho paquete.
Si no tenemos datamedios instalado podemos hacerlo en la terminal de R con:
[[CODE:r]]
install.packages("datamedios")
[[/CODE]]
Cargar librerías necesarias
Para efectos de este tutorial cargaremos las siguientes librerías
[[CODE:r]]
library(datamedios)
library(dplyr)
library(stopwords)
library(ggplot2)
library(lubridate)
# Verificar versión del paquete
packageVersion("datamedios")
[[/CODE]]
Extracción de Datos sobre "Sequía"
El paquete `datamedios` tiene dos funciones principales de extracción. Una extrae por cantidad máxima de resultados y otra por cantidad de fechas. En el presente ejemplo para el tutorial utilizaremos esta última variante, para tomar un periodo de tiempo específico y porque no necesitamos acotar la cantidad de datos a extraer.
Alternativamente, se podría hacer lo mismo utilizando la función `extraer_noticias_max_res`, e incluso si no le damos el parámetro `max_results` podríamos descargar todas las noticias disponibles.
Extraer noticias sobre sequía entre 2020 y 2024
Usaremos un rango de fechas amplio para capturar suficientes datos. El parámetro subir_a_bd lo dejaremos en FALSE por ahora para no interactuar con base de datos. Adem´s utilizamos múltiples fuentes para comparar.
[[CODE:r]]
noticias_sequia <- extraer_noticias_fecha(
search_query = "sequía",
fecha_inicio = "2020-01-01",
fecha_fin = "2024-12-31",
subir_a_bd = FALSE,
fuentes = "bbcl, emol, mediosregionales"
)
[[/CODE]]
Mostramos información básica sobre los datos extraídos
[[CODE:r]]
cat("Total de noticias extraídas:", nrow(noticias_sequia), "\n")
cat("Fuentes incluidas:", unique(noticias_sequia$medio), "\n")
[[/CODE]]
Así, obtenemos 1921 observaciones, es decir, 1921 noticias, con 12 columnas y con la columna `contenido_limpio` en `NA` por el momento.
Preparación y limpieza de datos
Las noticias muchas veces vienen con contenido "basura" que no nos sirve, como bloques que dicen "Lee también" y llevan a otras notas que a veces no tienen que ver con lo que estamos buscando, así como etiquetas HTML (<div>, <p>, etc.) que solo contaminan el texto a la hora de hacer análisis del contenido. Por eso el paquete datamedios viene con funciones específicas para limpiar los datos de las noticias, específicamente para los formatos en los que se extraen los datos de sus fuentes soportadas:
[[CODE:r]]
# Limpiar el contenido de las noticias para análisis posterior
noticias_limpias <- limpieza_notas(
noticias_sequia,
sinonimos = c("escasez",
"déficit hídrico",
"falta de agua",
"crisis del agua",
"crisis hídrica")
)
# Verificar el resultado de la limpieza
cat("Noticias después de limpieza:", nrow(noticias_limpias), "\n")
cat("Columnas disponibles:", paste(colnames(noticias_limpias), collapse = ", "), "\n")
# Explorar la distribución por medio
distribucion_medios <- noticias_limpias %>%
count(medio, sort = TRUE)
print("Distribución de noticias por medio:")
print(distribucion_medios)
# Verificar que tenemos contenido limpio
cat("\nEjemplo de contenido limpio (primeros 200 caracteres):\n")
cat(substr(noticias_limpias$contenido_limpio[1], 1, 200), "...\n")
[[/CODE]]
Con esto, obtenemos un dataframe `noticias_limpias` con 12 columnas, pero esta vez tenemos el contenido limpio en la columna `contenido_limpio`, a la cual podemos acceder llamando a `noticias_limpias$contenido_limpio`.
Nuestros casos disminuyeron a 1596 luego de la limpieza, lo que es completamente normal, ya que muchas noticias aparecen dentro de la extracción por falsos positivos derivados de links a otras noticias. Ahora podremos continuar a nuestra primera visualización.
Gráfico Noticias Por Mes
[[CODE:r]]
# Crear gráfico temporal para visualizar la evolución de la cobertura
grafico_temporal <- grafico_notas_por_mes(
datos = noticias_limpias,
titulo = "Cobertura Mediática sobre Sequía en Chile (2020-2024)",
fecha_inicio = "2020-01-01",
fecha_fin = "2024-12-31"
)
# Mostrar el gráfico
print(grafico_temporal)
# Análisis adicional: identificar picos de cobertura
noticias_por_mes <- noticias_limpias %>%
mutate(fecha = as.Date(fecha)) %>%
mutate(mes_año = floor_date(fecha, "month")) %>%
count(mes_año, sort = TRUE)
cat("Meses con mayor cobertura sobre sequía:\n")
print(head(noticias_por_mes, 5))
[[/CODE]]
Generamos el siguiente gráfico:
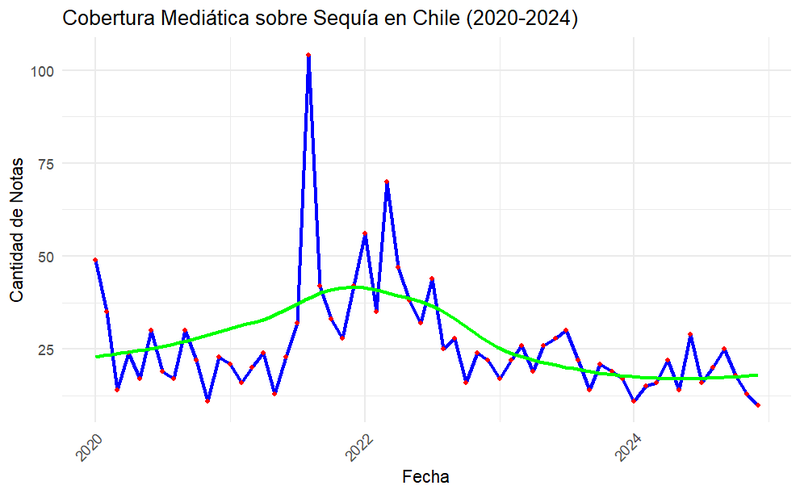
Además, podemos ver que los meses con mayor cantidad de notas son:
- 2021-08 -> 104 notas
- 2022-03 -> 70 notas
- 2022-01 -> 56 notas
- 2020-01 -> 49 notas
- 2022-04 -> 47 notas
Con esto ya podemos hacer una estrategia de buscar noticias en los momentos en los que más han habido y donde más se ha puesto de relieve en la discusión pública mediante estos medios de prensa.
Nube de Palabras
También podemos generar una nube de palabras con la función word_cloud de datamedios, una función creada con wordcloud2 pero adaptada al paquete para que funcione directamente con la estructura de nuestros dataframes de noticias. Aquí utilizamos stopwords, es decir, palabras que no queremos incluir dentro del conteo de palabras, ya que no aportan mucho contexto o significado (tales como artículos definidos, indefinidos, preposiciones, etc.), o porque para nuestro caso no sirven mucho. En nuestro caso, agua o sequí son palabras que aparecerán sí o sí y no nos interesa mucho saber que aparecerán, porque ya lo sabemos. Lo que nos interesa es saber a qué palabras se encuentran más relacionadas.
[[CODE:r]]
# Podemos obtener un listado genérico de
stop_words_es <- stopwords("es", source = "snowball")
# Definir stopwords adicionales específicas para nuestro análisis
stop_words_adhoc <- c("chile", "sequía", "agua", "https", "2021", "2022", "media.biobiochile.cl", "país", "región", "año", "años", "millones", "nacional", "según", "además", "ser", "aguas", "2", "12","30", "2020", "20", "10", "va", "wp", "mp3", "bío", "2019", "2023", "si", "3", "1", "cómo", "así", "día", "content")
# Combinar ambos vectores eliminando duplicados
stop_words_final <- unique(c(stop_words_es, stop_words_adhoc))
# Generar la nube de palabras con stopwords combinadas
datamedios::word_cloud(
datos = noticias_limpias,
max_words = 200,
stop_words = stop_words_final
)
[[/CODE]]

Análisis extra
Adicionalmente podemos manipular los dataframes como queramos. Por ejemplo, para hacer un análisis comparativo de la cobertura sobre la sequía por medio sin usar las funciones del paquete.
[[CODE:r]]
# Preparar datos mensuales por fuente
noticias_mensuales <- noticias_limpias %>%
mutate(fecha = floor_date(as.Date(fecha), "month")) %>%
count(fecha, medio, name = "cantidad") %>%
arrange(fecha)
# Crear secuencia completa de meses para cada medio
fechas_completas <- seq(from = min(noticias_mensuales$fecha),
to = max(noticias_mensuales$fecha),
by = "month")
medios_unicos <- unique(noticias_mensuales$medio)
# Crear grid completo de meses x medios
grid_completo <- expand.grid(fecha = fechas_completas, medio = medios_unicos,
stringsAsFactors = FALSE)
# Unir con datos reales y rellenar con 0 donde no hay noticias
noticias_mensuales_completo <- grid_completo %>%
left_join(noticias_mensuales, by = c("fecha", "medio")) %>%
mutate(cantidad = ifelse(is.na(cantidad), 0, cantidad))
if(length(medios_unicos) <= 3) {
colores_medios <- c("bbcl" = "#00ffff",
"emol" = "#ff9900",
"mediosregionales" = "#00ff00")[medios_unicos]
} else {
# Para más de 3 medios, usar paleta automática
colores_medios <- RColorBrewer::brewer.pal(min(length(medios_unicos), 11), "Spectral")
names(colores_medios) <- medios_unicos
} # Por si usas una versión de datamedios superior a la 1.2.1 en un futuro
# con más fuentes disponibles o si usas también la guioteca
# Crear gráfico de líneas por fuente
grafico_comparativo_mensual <- ggplot(noticias_mensuales_completo,
aes(x = fecha, y = cantidad, color = medio)) +
geom_line(linewidth = 0.7, alpha = 0.8) +
geom_point(size = 1, alpha = 0.9) +
geom_smooth(method = "loess", se = FALSE, linewidth = 1.5, alpha = 0.7) +
scale_color_manual(values = colores_medios) +
labs(
title = "Evolución Mensual de Cobertura sobre Sequía por Fuente (2020-2024)",
x = "Fecha",
y = "Número de Noticias por Mes",
color = "Fuente",
caption = "Datos extraídos con paquete datamedios 1.2.1"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 14, face = "bold"),
plot.subtitle = element_text(hjust = 0.5, size = 11, color = "grey60"),
axis.text.x = element_text(angle = 45, hjust = 1),
legend.position = "bottom",
panel.grid.minor = element_blank(),
plot.caption = element_text(size = 9, color = "grey50")
) +
scale_x_date(date_breaks = "3 months", date_labels = "%Y-%m") +
scale_y_continuous(breaks = scales::pretty_breaks(n = 6))
# Mostramos el gráfico
print(grafico_comparativo_mensual)
# Análisis de picos mensuales por fuente
picos_mensuales_por_fuente <- noticias_mensuales %>%
group_by(medio) %>%
slice_max(cantidad, n = 3, with_ties = FALSE) %>%
arrange(medio, desc(cantidad)) %>%
mutate(
fecha_formato = format(fecha, "%Y-%m"),
ranking = row_number()
) %>%
select(medio, fecha_formato, cantidad, ranking)
# Estadísticas
cat("\nEstadísticas descriptivas:\n")
resumen_por_medio <- noticias_mensuales %>%
group_by(medio) %>%
summarise(
total_noticias = sum(cantidad),
promedio_mensual = round(mean(cantidad), 1),
mediana_mensual = median(cantidad),
max_mensual = max(cantidad),
meses_activos = n(),
.groups = "drop"
)
if(require(knitr, quietly = TRUE)) {
print(knitr::kable(resumen_por_medio,
col.names = c("Medio", "Total", "Prom./Mes", "Mediana",
"Máximo", "Meses Con Notas")))
} else {
print(resumen_por_medio)
}
[[/CODE]]
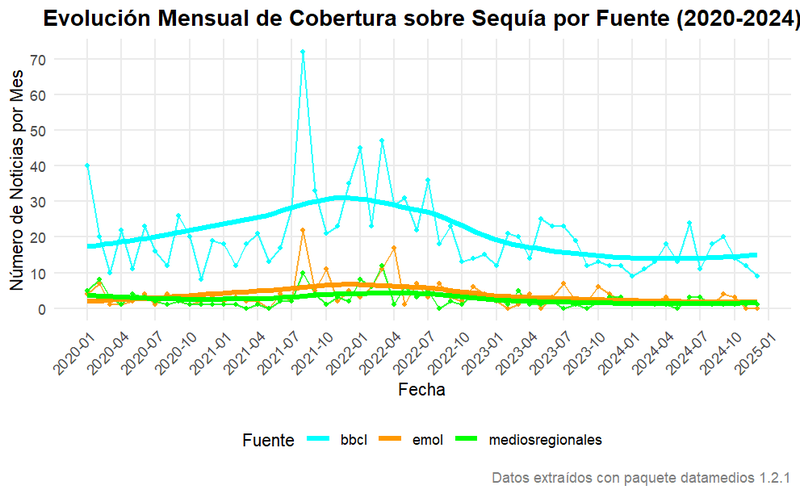
Obtenemos este gráfico comparativo entre los medios que muestra claramente la gran cantidad de producción de notas de BíoBío respecto de las otras fuentes. Además, al ejecutar este bloque de código obtenemos estadísticos descriptivos comparativos para cada medio en R. Podemos usar el conjunto de estos datos para hacer revisiones más meticulosas por fecha sobre eventos relacionados a la sequía en los picos de producción de notas, así como analizar las tendencias.
Función `agregar_datos_unicos`
Al inicio, cuando hicimos la extracción de datos, dejamos el parámetro `subir_a_bd` = FALSE. Esto implica que al momento de la extracción no estamos enviando datos a nuestra base de datos. Adicionalmente, si quieres ayudar a poblar la base de datos que utilizamos para entregar el dashboard de datamedios, puedes utilizar la función `agregar_datos_unicos`. Para eso, simplemente podemos poner desde un inicio el parámtro en TRUE o también podemos usar la función:
[[CODE:r]]
agregar_datos_unicos(noticias_sequia)
[[/CODE]]
A modo de conclusión
En este tutorial hemos intentado resumir el potencial del paquete `datamedios` a la vez que mostrar de forma acotada el flujo de sus funciones y la estructura de sus dataframes. A través del caso de estudio sobre la sequía, hemos explorado cómo extraer, procesar y analizar datos de noticias desde múltiples fuentes chilenas.
En cuanto a los hallazgos específicos de este ejemplo, el análisis reveló patrones temporales significativos en la cobertura de las sequías, con picos notables durante agosto de 2021 y los primeros meses de 2022, coincidiendo -hasta donde sabemos- con periodos de mayor intensidad de la crisis hídrica en el país. La distrubución de la cobertura mostró una clara predominancia de BíoBío Chile como la fuente principal (algo que suele ocurrir en la mayoría de los casos que hemos probado hasta el momento), representando aproximadamente un 77% del total de noticias analizadas.
El análisis mediante la nube de palabras facilitó la identificación de términos clave asociados que llegan más allá del concepto central de sequía o de sus "sinónimos", sino que también revela dimensiones geográficas específicas, sectores económicos afectados y algunas ligadas a instituciones, sobre todo políticas, ayudando a ajustar la puntería para estudios más extensivos, lo que aporta un valor metodológico importante a la hora no solo de disponer de grandes corpus de datos para realizar estudios, sino que también para hacer aproximaciones iniciales a esos datos y pensar puntos de vista específicos para las problemáticas que buscamos investigar.
La metodología presentada en este tutorial, así como el flujo de uso de las funciones del paquete, son escalables y adaptables a otros temas de interés público y social, estableciendo un marco cuantitativo robusto para futuras investigaciones en comunicación, análisis de contenido mediático en el contexto chileno, investigaciones en el área de la sociología o de otras disciplinas como la lingüística.
¡Ahora te toca a ti!