
Introducción
En un artículo anterior, presentamos datamedios, un paquete de R que permite buscar y descargar noticias de medios de prensa. En esta ocasión, te mostraré una base de datos que hemos estado construyendo, a partir, justamente, de las descargas de datamedios.
Diariamente, obtenemos textos periodísticos de algunos medios de prensa y los vamos almacenando en una base de datos. Ya tenemos casi 900.000 noticias, que pueden explorarse en una aplicación que hemos construido y que está disponible acá, pero estamos seguros de que puede sacarse aún mucho más provecho de esta fuente de información. Es por ello que nos gustaría que la comunidad acceda a los datos y haga sus propios análisis[1].
En este tutorial, exploraremos juntos el contenido de nuestro dataset y cómo acceder a él. Al final, te recomendaré algunas herramientas útiles para procesar los datos en R de forma sencilla.
Explorando los datos
El foco de este tutorial no es la conexión a bases de datos, pero es relevante que sepas que los datos viven en un motor relacional (Mysql) y en una base de datos no relacional (elasticsearch). En esta ocasión nos conectaremos a mysql, solo para tener una primera mirada de los datos, ya que luego de ello, seguiremos trabajando localmente con un archivo parquet.
Generamos una conexión a la base de datos, usando el paquete DBI. Naturalmente, las credenciales están ocultas, pero si lo solicitas, podemos darte acceso (al final del tutorial te explico cómo acceder a la base de datos).
[[CODE:r]]
library(DBI)
con <- dbConnect(
RMySQL::MySQL(),
dbname = Sys.getenv("DATABASE"),
host = Sys.getenv("HOST") ,
port = as.integer(Sys.getenv("PORT")) ,
user = Sys.getenv("USER") ,
password = Sys.getenv("PASSWORD")
)
[[/CODE]]
La tabla noticias contiene las noticias que hemos ido descargando durante las últimas semanas. Para explorar los datos usaremos una herramienta de R que permite hacer queries a una base de datos, sin tener que escribir directamente código de SQL. La herramienta específica se llama dbplyr, que funciona como backend de dplyr, por lo que debes tener instalados ambos paquetes antes de seguir.
Comencemos mirando el número de filas que contiene la tabla noticias. Debes notar que al final de la consulta usamos collect(). Esta función tiene el propósito de traer los datos desde la base a nuestra sesión de R. La consulta devuelve 877.798 filas, es decir, el número de noticias descargadas en el momento en que este tutorial fue escrito.
[[CODE:r]]
# Referencia a una tabla remota
tabla_remota <- tbl(con, "noticias")
# Traemos las primeras filas de la tabla
n_rows = tabla_remota %>%
summarise(total = n()) %>%
collect()
[[/CODE]]
[[CODE:r]]
total
1 877798
[[/CODE]]
Dado que la tabla tiene un número considerable de filas, traeremos solo las primeras 100, para revisar la información de manera aǵil.
[[CODE:r]]
# Traemos las primeras filas de la tabla
head_100 = tabla_remota %>%
head(100) %>%
collect()
[[/CODE]]
Las columnas contenido y contenido_limpio contienen el texto de las noticias, en su versiones bruta y limpia, respectivamente. Por su parte, id corresponde al identificador único, fecha indica el momento de publicación y medio contiene la información sobre el medio de prensa que publica la noticia. El resto de las columnas no las utilizaremos por el momento.
[[CODE:r]]
names(head_100)
[[/CODE]]
[[CODE:r]]
[1] "id" "titulo" "contenido" "temas" "url" "url_imagen"
[7] "autor" "fecha" "resumen" "contenido_limpio" "medio" "created_at"
[13] "updated_at"
[[/CODE]]
Veamos un ejemplo de una noticia bruta versus una limpia. Podrás notar que la versión original contiene varias etiquetas html que no necesariamente son útiles para el análisis, por lo que hemos decidido removerlas y dejar un texto un poco más limpio en contenido_limpio. Si bien, seguirás teniendo algunos caracteres poco útiles (como el backslash), el punto de partida para posteriores análisis es mucho más amigable que comenzando con los datos brutos.
[[CODE:r]]
[1] "<div>El mes que acaba de pasar fue el <b>septiembre más caluroso que se ha registrado en el mundo</b>, anunció este martes el servicio sobre cambio climático del programa europeo Copérnico</div><div><br></div><div>\"A nivel mundial,<b> septiembre de 2020 estuvo 0,05 °C por encima de septiembre de 2019, el mes más caluroso hasta ahora registrado</b>\", indica el servicio europeo. Es decir 0,63 °C por encima de la media del periodo 1981-2020. </div><div><br></div><div><b>Las temperaturas fueron especialmente elevadas en Siberia</b>, siguiendo la estela de una ola de calor que empezó en primavera y que favoreció una serie de incendios espectaculares. </div><div><br></div><div><b>El calor fue también más fuerte de lo normal en el océano Ártico</b>, señala el servicio, que recuerda que este año el deshielo de la banquisa de verano en el Ártico terminó como la segunda superficie más pequeña de la historia, después de la de 2012. \"La combinación 2020 de temperaturas récord y de una banquisa de verano a un nivel bajo pone de manifiesto la importancia de mejorar el control en una región que se calienta más rápido que el resto en el mundo\", comenta Carlo Buontempo, director del servicio europeo sobre cambio climático.</div><div><br></div><div>Norteamérica también tuvo un mes de septiembre muy caluroso, sobre todo con los 49 °C registrados a principios de mes en <b>California, que fue devastada por los incendios</b>.</div><div><br></div><div>La entidad señaló además que <b>2020 podría ser el año más caluroso, desplazando a 2016</b>. El período de doce meses que va de octubre de 2019 a septiembre de 2020 se sitúa 1,28°C por encima de las temperaturas de la era preindustrial, acercando al planeta al techo de 1,5 grados, el objetivo más ambicioso del acuerdo de París tendiente a limitar los impactos devastadores del cambio climático.</div><div><br></div><div>La temperatura del planeta ya ha aumentado más de 1 °C y se incrementa una media de 0,2 °C por década desde finales de los años 1970, insiste Copernicus en su balance climático mensual. Y 2020 no va a cambiar la tendencia, ya que incluye los meses de enero, mayo y junio más cálidos. </div>"
[1] "El mes que acaba de pasar fue el septiembre más caluroso que se ha registrado en el mundo, anunció este martes el servicio sobre cambio climático del programa europeo Copérnico \"A nivel mundial, septiembre de 2020 estuvo 0,05 °C por encima de septiembre de 2019, el mes más caluroso hasta ahora registrado\", indica el servicio europeo. Es decir 0,63 °C por encima de la media del periodo 1981-2020. Las temperaturas fueron especialmente elevadas en Siberia, siguiendo la estela de una ola de calor que empezó en primavera y que favoreció una serie de incendios espectaculares. El calor fue también más fuerte de lo normal en el océano Ártico, señala el servicio, que recuerda que este año el deshielo de la banquisa de verano en el Ártico terminó como la segunda superficie más pequeña de la historia, después de la de 2012. \"La combinación 2020 de temperaturas récord y de una banquisa de verano a un nivel bajo pone de manifiesto la importancia de mejorar el control en una región que se calienta más rápido que el resto en el mundo\", comenta Carlo Buontempo, director del servicio europeo sobre cambio climático. Norteamérica también tuvo un mes de septiembre muy caluroso, sobre todo con los 49 °C registrados a principios de mes en California, que fue devastada por los incendios. La entidad señaló además que 2020 podría ser el año más caluroso, desplazando a 2016. El período de doce meses que va de octubre de 2019 a septiembre de 2020 se sitúa 1,28°C por encima de las temperaturas de la era preindustrial, acercando al planeta al techo de 1,5 grados, el objetivo más ambicioso del acuerdo de París tendiente a limitar los impactos devastadores del cambio climático. La temperatura del planeta ya ha aumentado más de 1 °C y se incrementa una media de 0,2 °C por década desde finales de los años 1970, insiste Copernicus en su balance climático mensual. Y 2020 no va a cambiar la tendencia, ya que incluye los meses de enero, mayo y junio más cálidos."
[[/CODE]]
Para terminar esta sección, echemos un vistazo a las columnas medio y fecha. Las tablas muestran que tenemos noticias de al menos 3 medios (en el resto de las filas pueden haber más) y que las fechas se construyen con el formato año-mes-día.
[[CODE:r]]
medio n
1 bbcl 3
2 emol 96
3 guioteca 1
[[/CODE]]
[[CODE:r]]
fecha n
2002-12-07 4
2002-12-08 2
2012-09-01 3
2018-03-10 1
2020-10-06 2
2020-10-07 67
2020-10-08 20
2020-10-09 1
[[/CODE]]
Procesando los datos
Ya sabemos de dónde provienen los datos y conocemos algunas de sus características, lo cual es un buen punto de partida para lo que te mostraré en esta última sección.
Trabajaremos con un archivo que fue exportado previamente de la base de datos y que contiene únicamente las columnas que comentamos más arriba, pero excluyendo aquella con noticias sin editar (para ahorrar recursos). Las columnas, entonces, son las siguientes: id, fecha, medio y contenido_limpio.
El formato de archivo es parquet y lo utilizaremos debido a que es muy eficiente para trabajar con grandes volúmenes de datos. Parquet utiliza un tipo de almacenamiento columnar, que permite realizar consultas y análisis de datos de manera muy rápida. Si te interesa conocer más sobre las características de parquet, puedes revisar este artículo
En R contamos con varias herramientas para cargar datos con formato parquet, dentro de las cuales quizá la más usual sea el paquete arrow. Mediante la función read_parquet podemos leer el archivo noticias_respaldo.parquet. Debes notar que el parámetro as_data_frame tiene el valor FALSE. Con ello le indicamos a R que no cargue en memoria los datos como un dataframe estándar, sino como una tabla arrow, lo cual nos permitirá aprovechar el rendimiento de este formato.
[[CODE:r]]
# Cargamos la librería
library(arrow)
# Traemos las primeras filas de la tabla
parquet_table = read_parquet("data/noticias_respaldo.parquet", as_data_frame = FALSE)
[[/CODE]]
Una vez cargado, podemos hacer operaciones como agrupar y contar, tal como se muestra más abajo.
[[CODE:r]]
parquet_table %>%
group_by(medio) %>%
summarise(total = n()) %>%
collect()
[[/CODE]]
El tiempo de ejecución para tareas de procesamiento de texto es bastante aceptable, considerando que estamos trabajando con un volumen de datos importante. Por ejemplo, podemos buscar todas las noticias que contienen la palabra delincuencia.
[[CODE:r]]
library(stringr)
library(tictoc)
tic()
conteo = parquet_table %>%
filter(str_detect(contenido_limpio, "delincuencia")) %>%
summarise(total = n()) %>%
collect()
toc()
[[/CODE]]
[[CODE:r]]
0.838 sec elapsed
[[/CODE]]
Podemos contar el número de veces que aparece la palabra delincuencia (o cualquier otro término) en Biobio y Emol.
[[CODE:r]]
conteo_medios = parquet_table %>%
filter(medio == "emol" | medio == "bbcl" ) %>%
filter(str_detect(contenido_limpio, "delincuencia")) %>%
group_by(medio) %>%
summarise(total = n()) %>%
collect()
[[/CODE]]
El paquete arrow es una opción cómoda para trabajar con archivos parquet, pero en la medida en que vayamos recolectando más noticias, es posible que deje de ser una estrategia viable para procesar los datos en computadores con pocos recursos. Es por ello que revisaremos una herramienta llamada duckdb, que puede ser una buena alternativa si cuentas con pocos recursos de hardware.
Duckdb es un motor de base de datos que permite ejecutar consultas SQL sobre archivos locales. Es muy eficiente y se integra bien con R, permitiéndonos trabajar con grandes volúmenes de datos sin necesidad de cargar todo en memoria.
Lo primero que debemos hacer es instalar el paquete duckdb, si es que aún no lo tienes. Luego, crearemos una conexión a la base de datos y leeremos el archivo parquet como una tabla virtual, mediante las siguientes líneas.
[[CODE:r]]
# Conectarse a DuckDB
con <- dbConnect(duckdb::duckdb(), dbdir = "data/noticias.db")
# Leer el parquet como una tabla virtual usando dplyr
datos <- tbl(con, sql("SELECT * FROM parquet_scan('data/noticias_respaldo.parquet')"))
[[/CODE]]
La función parquet_scan debe ser usada en una sentencia de SQL y solo necesita que se indique el directorio en el cual se ubica el archivo que queremos cargar. De aquí en adelante no es necesario seguir usando directamente código de SQL, ya que, al igual que con la primera conexión a Mysql, podemos usar verbos de dplyr para manipular los datos sin necesidad de cargar todo en memoria.
[[CODE:r]]
# Usar verbos dplyr como si fuera un data.frame
conteo <- datos %>%
filter(str_detect(contenido_limpio, "delincuencia")) %>%
summarise(total = n()) %>%
collect()
[[/CODE]]
Para terminar este tutorial, consultaremos la base de datos para obtener el número de noticias diarias publicadas en Emol y Biobio desde el año 2010. A partir de ese resultado, podemos hacer un pequeño procesamiento, con el propósito de agrupar los datos a nivel de mes, para luego crear un gráfico con ggplot.
[[CODE:r]]
library(ggplot2)
library(lubridate)
conteo_fecha <- datos %>%
filter(medio == "bbcl" | medio == "emol") %>%
filter(fecha >= "2010-01-01") %>%
group_by(fecha, medio) %>%
summarise(total = n()) %>%
collect()
conteo_fecha %>%
mutate(mes = floor_date(fecha, unit = "month") ) %>%
group_by(mes, medio) %>%
summarise(total = sum(total) ) %>%
ggplot(aes(x = mes, y = total, group = medio, colour = medio)) +
geom_line()
[[/CODE]]
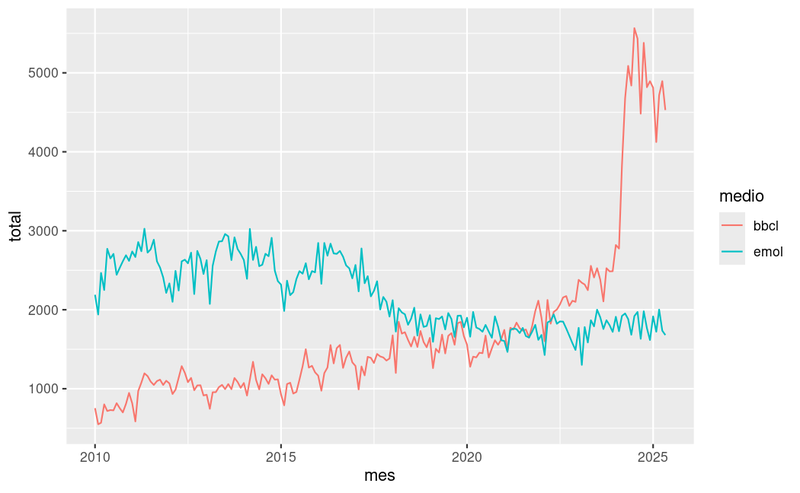
Finalmente, nos desconectamos de la base de datos para liberar los recursos.
[[CODE:r]]
dbDisconnect(con)
[[/CODE]]
Al cierre
El objetivo de este artículo ha sido describir el dataset de noticias que estamos construyendo y mostrarte dos herramientas útiles para hacer análisis con R. Si estás interesado o interesada en trabajar con esta fuente de información, puedes descargar el dataset en este link. Iremos publicando archivos con datos actualizados constantemente, pero en caso de que necesites acceso a datos con periodicidad diaria, escríbenos a Instagram o a nuestro correo, para gestionar el acceso a la base de datos.
Notas
[1]: Al momento de hacer análisis es importante conocer la metodología que utilizamos para recolectar las noticias, ya que algunas decisiones podrían implicar ciertos sesgos involuntarios. El paquete datamedios se conecta a las API de los distintos medios y a partir de un listado de aproximadamente 300 strings, se hacen búsquedas para descargar todas las noticias que contienen los términos de dicho listado, el cual fue construido con el objeto de abarcar la mayor cantidad de temas posibles, sin embargo, no es posible garantizar la ausencia de sesgos. Para más detalles sobre la metodología de descarga, revisa este repositorio.